
Im Rahmen meines Seminars zum Thema Realtime E-Commerce Performance Messung habe ich mich mit den möglichen externen Key Performance Indicators (KPI) beschäftigt, die man zum Beispiel als Grundlage einer Konkurrenzanalyse nutzen kann, sowie einen Prototypen als Proof-Of-Concept entwickelt. Die hierbei anfallenden Daten habe ich im Anschluss ausgewertet und so unter Anderem die Aktivität nach Plattform analysiert.
Quellen für KPIs
Als erstes habe ich mir die Frage gestellt, welche KPIs man überhaupt von möglichen Mitbewerbern messen kann. Da man weder Kontrolle über die Plattform der Konkurrenz noch ihrer Tools hat, fallen die typisches Messungen mit Google Analytics etc. weg. An Interna wie Verkaufszahlen eines Onlineshops kommt man ebenfalls nicht ohne erheblichen Aufwand und Messungenauigkeiten heran. Um dennoch Informationen über die Kunden eines Onlineshops zu bekommen, bietet es sich insbesondere im Endkundenbereich (B2C) an, sich den Kunden selber und seine Interaktionen mit der Marke anzuschauen.
Dies lässt sich dank der starken Verbreitung von Social Media einfach realisieren, da ein Großteil der Interaktionen zwischen Kunden und Marke/Onlineshop öffentlich stattfindet. Dazu machen quasi alle gängigen Sozialen Netzwerke diese Kommunikation über Schnittstellen zugänglich. Aus diesem Grund habe ich mich primär auf die Auswertung von Sozialen Netzwerken konzentriert. Hierfür habe ich exemplarisch Facebook, Twitter und Youtube als die erfolgreichsten Netzwerke ihrer Art ausgewählt.
Im nächsten Schritt ging es darum, Player aus bestimmten Bereichen aufzustellen, um eine Vergleichbarkeit sowohl innerhalb einer homogenen Gruppe – zum Beispiel Onlineshops aus dem Modebereich – als auch gruppenübergreifend zu gewährleisten. Hierfür habe ich folgende Gruppen aufgestellt und alle Präsenzen auf den genannten Sozialen Netzwerken zusammengestellt:
- erfolgreiche Youtuber aus Deutschland (gemessen an Abonennenten und Videoaufrufe)
- Marken auf Facebook mit den meisten Fans
- Onlineshops aus dem Bereich (Computer-)Technik
- Onlineshops aus dem Bereich Mode
- Firmen aus der Fitnessbranche, darunter sowohl Fitnessstudios als auch führende B2B Hersteller
Alle ausgewählten Firmen haben gemeinsam, dass sie entweder aus Deutschland selber kommen oder aber Deutschland zumindest ein Schlüsselmarkt darstellt.
Insgesamt bin ich so auf knapp 100 verschiedene Firmen gekommen, die ich über vier Wochen mit dem Tracking-Frameworks die Aktivität überwacht und ausgewertet habe.
Prototyp des Tracking-Frameworks
Software


Das System setzt sich aus dem Webserver NGINX, der relationellen Datenbank MariaDB (Fork der beliebten MySQL-Datenbank), der Dokumentendatenbank MongoDB und schließlich der PHP-7.2-Runtime zusammen, in welcher der eigentliche Anwendungscode läuft.
Zum besseren Verständnis einmal kurz eine Erklärung zu den einzelnen Komponenten:
![]()

![]()

![]()



Symfony Framework
In meinem Beruf habe ich bereits viel Erfahrung mit dem PHP-Framework Symfony gesammelt. Dies ist durch seinen stark modularen Aufbau auch die Grundlage vieler moderner PHP-Projekte, weswegen es die Basis für den Prototypen stellt. Dadurch konnte ich auf das große Ökosystem um das PHP-Framework zurückgreifen und nutze für die Datenbankabstraktion Doctrine sowie darauf aufbauend das Paket API Platform. Dieses erzeugt aus den Doctrine-Datenbankmodellen automatisch eine REST-Schnittstelle. Diese ermöglicht die Verwaltung samt Berechtigungsverwaltung über entsprechende Tools wie dem in API Plattform vorhandenen API-Client ohne großen Entwicklungsaufwand.
Aufbau/Programmierung
Das relationelle Datenbankmodell beschränkt sich im Prototypen auf die Verwaltung der einzelnen Ressourcen auf den Sozialen Netzwerken sowie ihre Zusammenfassung in Kollektionen, was eine Sammlung aller medialen Präsenzen eines der untersuchten Unternehmen darstellt. Diese Kollektionen können wiederum vom Nutzer in Projekten gesammelt werden. Bei Gruppen wären das zum Beispiel die Onlineshops im Bereich Mode, die so einfach verglichen werden können.
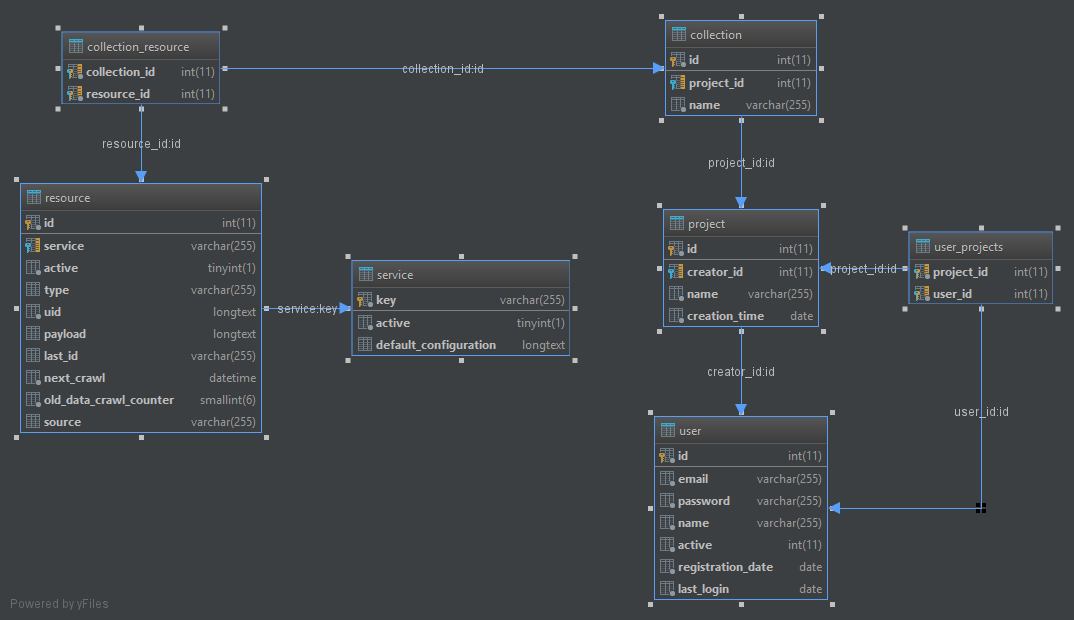
Der eigentliche Kern der Anwendung besteht jedoch aus dem periodischen Abrufen der Informationen über die öffentlichen APIs der untersuchten Netzwerke. Dies hat den Vorteil, dass eine Anfrage stets den gleichen Aufbau hat und einfach maschinell weiterverarbeitet kann. Dem steht der Ansatz gegenüber, private APIs oder direkt den Webseiteninhalt abzurufen. Dise haben den Nachteil, dass sich Inhalte und Endpunkte jederzeit ändern können. Somit würde das gesamte Verfahren nicht mehr wie gewünscht funktioniert.
Über einen sogenannten Scheduler werden mit mehrerer Strategien die einzelnen Ressourcen bewertet und im Anschluss mit einem Crawler abgefragt. Dieser Crawler ist ein kleines Programm, welches die API des Netzwerkes abruft, die Antwort für die weitere Auswertung in der MongoDB speichert und mögliche Informationen für weitere relevante Ressourcen extrahiert.
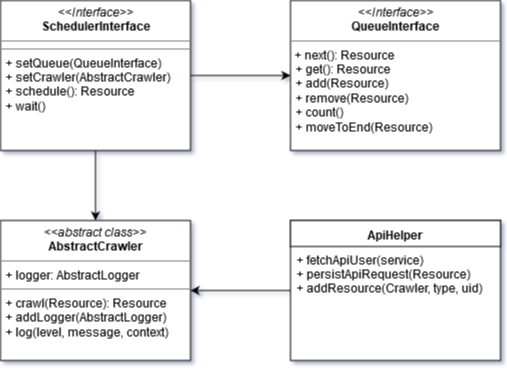
Scheduling
Mit dem Prototypen ist es nun möglich, Daten zu sammeln. Wie zuvor erwähnt müssen jedoch die einzelnen Ressourcen verwaltet werden, da alle überwachten Dienste Restriktionen („API Limits“) für ihre Schnittstellen haben. Außerdem wächst die Datenmenge bei höchstmöglicher Rate enorm an ohne einen Mehrwert zu bieten. Daher wird jede Art von Ressource daraufhin bewertet, wie häufig eine Änderung zu erwarten ist und wie schnell man Änderungen aufgreifen will. So ändert sich die Facebook Zeitleiste im Vergleich zu den Kommentaren und Reaktionen zu einem Beitrag normalerweise seltener. Da jedoch ein neuer Post schnell erkannt und im Folgenden analysiert werden soll, muss hier dennoch mit einer hohen Frequenz gearbeitet werden. Gleichzeitig ist bei den Inhalten ein Abschwellen der Aktivität über die Zeit zu erwarten. Daher vergleiche ich bei jeder Abfrage das Ergebnis mit der vorherigen Abfrage und erhöhe bei gleichem Inhalt das Interval bis zum nächsten Abruf sukzessiv.
Trotz dieser Strategien habe ich in den ersten beiden Wochen mit 253 Datenpunkten (Facebook-Seite, Twitter-Profil, Youtube-Kanal) und weiteren 9976 sekundären Datenpunkten (veröffentlichte Beiträge und Videos) insgesamt über 10 Millionen Abfragen an die verschiedenen APIs gestellt. Dies führt zu etwas über 835000 Datensätzen in der MongoDB.
Datenanalyse
Doch was macht man jetzt mit den gesammelten Daten? Hier kommt eine native Funktion der MongoDB sehr gut zum Einsatz: MongoDB hat den MapReduce-Algorithmus direkt integriert. Bei MapReduce handelt es sich um zwei nacheinander ausgeführte Funktionen. Die erste (map) weisst den Datensätzen einen Schlüssel zu. Die zweite bildet im Anschluss alle Datensätze eines Schlüssel auf einen neuen Datensatz ab.
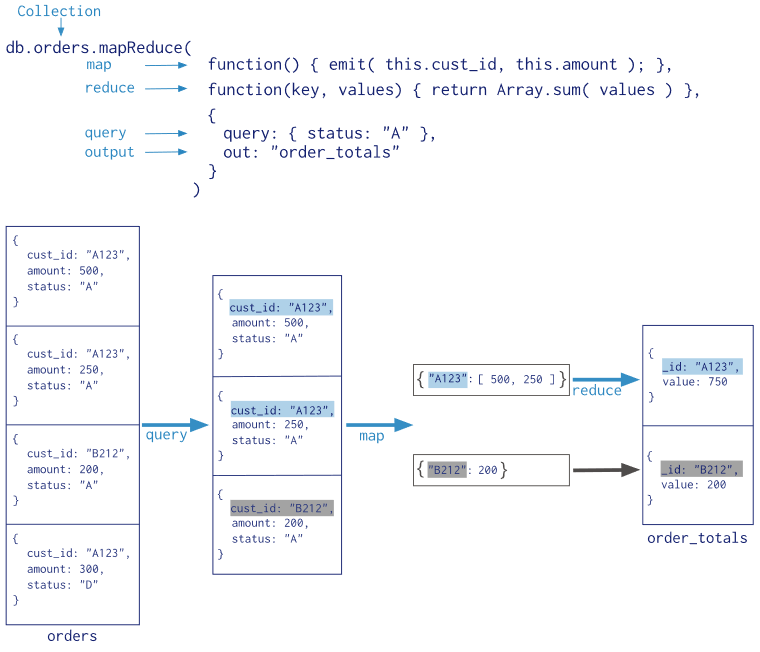
Darauf aufbauend habe ich dem Prototypen um ein Programm erweitert. Dieses lädt die gespeicherten Funktionen, führt sie aus und gibt das Ergebnis auf der Kommandozeile aus. Mit diesem Werkzeug habe ich dann analysiert, wie die generelle Aufteilung der Beiträge auf den jeweiligen Plattformen über den Tag und über die Woche aussieht:
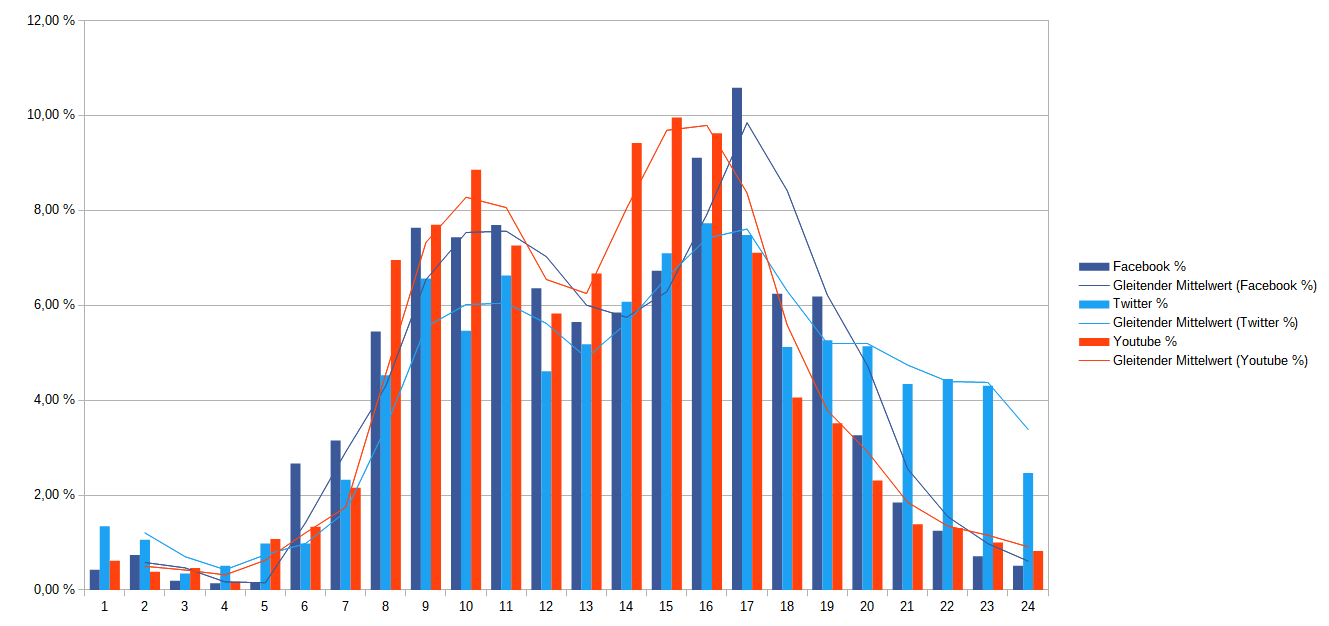
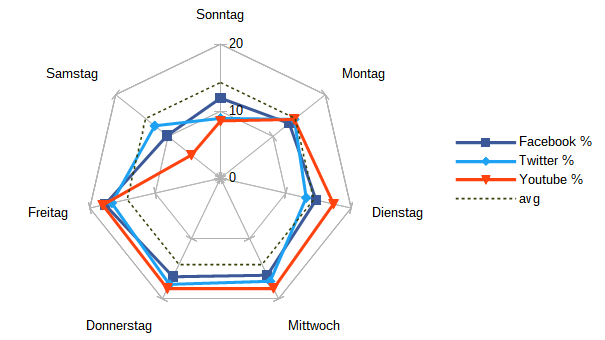
Beide Ergebnisse haben mich zwar nicht überrascht, da sie sich mit den typischen Arbeitszeiten einer 5-Tage Woche decken. Dennoch finde ich insbesondere die Nutzung von Twitter interessant, da diese anders als auf Facebook und Youtube deutlich länger in den Abend hinein stattfindet.
Für Interessierte findet sich der Prototyp unter https://github.com/pascalheidmann/realtime-perf-analytics.