Wann gehen Medien eigentlich viral? Welche Medien gehen viral? Und mit welchen Faktoren können wir steuern, dass ein Post, Bild oder Video möglichst viel Aufmerksamkeit bekommt? Wann handelt es sich um einen Buzz? Wie kann man einen Buzz erkennen?
Jeden Tag werden unzählige Beiträge in den sozialen Netzwerken verbreitet. Manche Beiträge erhalten kaum Impressionen während einige wenige Beiträge viral gehen. Sie haben einen erheblichen Effekt auf wirtschaftliche, soziale und politische Folgen.
Die folgende Studie widmet sich dieser Thematik und berichtet über das erste Buzz- Detection- System (BDS), dass zur Erkennung von Buzzes eingesetzt werden soll.
Was ist ein Buzz?
In der Studie werden zunächst zwei Arten von viralen Phänomenen unterschieden. Einerseits gibt es „Trendthemen“. Sie erfüllen die Eigenschaft der Unmittelbarkeit und Intensität. Beispiele hierfür sind Diskussionen über die letzte Fußballweltmeisterschaft sowie wiederkehrende Trendthemen wie z.B. Lotterien.
Andererseits gibt es „Buzzes“. Sie erfüllen nicht nur die Eigenschaften der Unmittelbarkeit und Intensität, sondern auch des Unerwarteten. Hier konzentriert man sich auf unerwartete Fälle. Somit ist es die erste Studie, die nicht Trendthemen, sondern „Buzzes“ behandelt.
Zudem unterscheidet man bei Buzzes von drei Arten:
- Feuerstürme: Beiträge die dem Image schaden. Unternehmen können dadurch erhebliche negative wirtschaftliche Konsequenzen erleiden.
- Liebesstürme: Hier handelt es sich um Beiträge, die positive Nachrichten/ Content verbreiten.
- Heiße Themen: Hier konfrontiert man Menschen mit kontroversen Themen.
Warum braucht man ein Buzz-Detection-System?
Man erhält durch das Buzz-Detection-System, welches Buzzes frühzeitig erkennt, eine Vielzahl an neuen Möglichkeiten. Ein Unternehmen kann so positive Auswirkungen maximieren und negative minimieren. Man kann so Inhalten schnell entgegenwirken, die dem Unternehmen schaden könnten.
Davon profitieren nicht nur die Unternehmen, sondern auch Personen des öffentlichen Lebens, Institutionen oder politische Parteien.
Sobald ein Beitrag in den Buzz-Bereich gelangt, können Werbeplattformen höhere Preise für die Platzierung von Anzeigen verlangen.
Außerdem kann man Facebook-Seiten analysieren, um die Wahrscheinlichkeit zu erhöhen, dass Beiträge zu Buzzes werden.
Social-Media-Manager können die Resultate des BDS nutzen, um die Buzzes zu analysieren, die Konkurrenten erzeugt haben.
Man kann entdeckte Buzzes zudem als Handlungsableitungen für Marketingstrategien nutzen. Praktiker können die Auswirkungen ihrer Buzzes in Bezug auf die Anzahl der gewonnenen Follower bestimmen oder des erwirtschafteten Umsatzes.
Einige politische Parteien möchten vielleicht, dass ihre Namen in laufenden Diskussion auftauchen, indem sie heiße Themen kommentieren, um ihre Positionen zu vertreten und andere von ihrer Seite zu überzeugen.
Das Ziel der Studie
Die Studie verfolgte 3 Ziele:
- Ein Konzept für die Buzz Erkennung entwickeln
- Eine prototypische Umsetzung
- Vermitteln von Faktoren für die frühzeitige Erkennung von Buzzes
Wie wurde der Forschungsnachfrage nachgegangen?
Die Studie stellt 3 verschiedene Ansätze auf.
Zunächst sammelt man Informationen, um herauszufinden, warum Inhalte viral gehen. Zweitens muss herausgefunden werden, welche Variablen ein Modell für die Vorhersage und Erkennung viraler Inhalte braucht.
Im Näheren konzentrieren sich Forscher auf die Identifizierung und das Verständnis von Variablen, die Online-Inhalte in den sozialen Medien vorantreiben und erklären, warum einige dieser mehr Aufmerksamkeit erhalten.
Schließlich folgt die Implementierung eines Erkennungssystems für Buzzes, um Verbesserungsmöglichkeiten zu erhalten.
Variablen für das Buzz-Detection-System
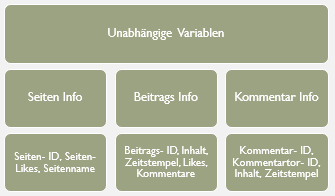
Um das Buzz-Detection-System zu realisieren, benötigt man unterschiedliche Variablen. Es werden manuell klassifizierte Daten (Buzz vs. Non- Buzz) als abhängige Variablen genutzt. Der Grund dafür ist die Eigenschaft der Unerwartetheit der Buzzes. Wenn man stattdessen sich auf Engagement-Variablen, wie z.B. der Anzahl der Likes, Kommentare oder Shares verlässt, lässt man diese Eigenschaft außer Acht. Zur Berechnung der Variablen untersuchen sie sechs Monate lang wiederholt 1.021 öffentliche Facebook-Seiten. Diese selektierten sie mit Hilfe eines Zufallsprinzips und News Seiten.
Neben den abhängigen Variablen waren unabhängige Variablen nötig, wie zum Beispiel die Anzahl der Seiten Likes oder Shares.
Architektur-Backend
Datenerhebung & Speicherung
Es wurden Metadaten von öffentlichen Facebook Seiten anhand von unabhängigen Crawlern erhoben und schließlich auf Servern gespeichert. Jeder dieser Crawler fungiert als registrierter Nutzer einer Facebook-App. Zu den gesammelten Daten gehören Aufrufe aller Kommentare und Beitragsseiten, sowie die Anzahl an Likes.
Um das zu realisieren, gibt es ein Planungsserver, der die Anfragen der Crawler nach bestimmten Kriterien priorisiert:
- Höchste erwartete Anzahl von Aktualisierungen.
- Zeitspanne, die seit der letzten Abfrage des Beitrags vergangen ist.
Allerdings besteht dann die Gefahr, dass man potentielle Buzzes nicht beachtet. Nun stellt sich die Frage, wie man trotzdem Beiträge mit geringerer Aktivität nicht ignoriert und wie man frühzeitig neue Beiträge entdeckt? Die Lösung für diese Herausforderung ist ein Algorithmus, der bestimmt, dass sich jede 20. Abfrage auf eine Seite beziehen muss und dass 10 % aller Abfragen auf die Aktualisierung der Beitragsseiten beschränkt ist.
Trainierte Modelle für die Buzz-Detektion
In der Studie verwenden sie verschiedene Methoden, mit denen man Buzzes erkennen kann. Sie nutzen dafür einerseits das Maschinen Learning (ML) für die Interpretation der Ergebnisse. Die Methode hat den Vorteil, dass man sie direkt anwenden kann, um Empfehlungen abzuleiten. Des Weiteren nutzen sie Lineare Regressionen (AdaBoost, Support Vector Machine & Random Forest) um besser klassifizieren zu können, ob es sich um ein Buzz handelt oder nicht. Dafür nutzen sie einen zusätzlichen Datensatz, um das Buzz-Detection-System zu trainieren.
Für die Klassifizierung haben vier Kodierer manuell und unabhängig voneinander Beiträge klassifiziert. Anschließend werden die Klassifizierungsergebnisse anhand der Korrelation verglichen. Falls die Korrelation der Kodierer über 0,7 betrug, galt das Ergebnis als eindeutig.
Architektur Frontend
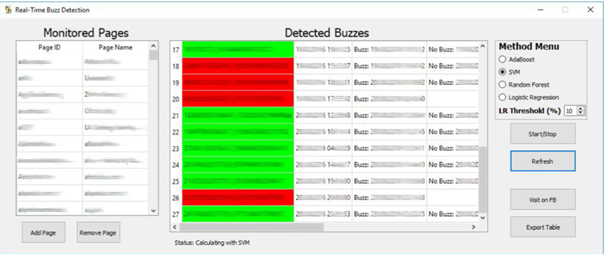
Dieses Bild stellt einen Screenshot vom Frontend des Buzz-Detection-Systems dar. So kann man es sich in der Anwendung vorstellen.
Das Frontend besteht aus der Seitentabelle (links), einer Buzz-Tabelle (Mitte), einem Methodenmenü (rechts) und einigen Buttons.
Die Seitentabelle beinhaltet alle Seiten, die das Buzz-Detection-System zu der Zeit überwacht.
Die Buzz-Tabelle listet alle erkannten Buzzes auf. Außerdem behält sie den Überblick über Beiträge, die einmal als Buzzes erkannt wurden, aber im Laufe der Zeit die Buzz-Kriterien nicht mehr erfüllen.
Die farblich markierten Zeilen sollen visualisieren, ob es sich derzeit um einen Buzz handelt oder nicht. Rot steht für einen Buzz und grün für einen Nicht-Buzz. Die Statuszeile informiert die Nutzer, ob das Buzz-Detection-System gerade im Berechnungsprozess ist, mit welcher spezifischen Methode gearbeitet wird, ob er „inaktiv“ ist und ob es auf Nutzerinteraktionen wartet.
Das Methodenmenü bietet dem Benutzer die Möglichkeit zwischen verschiedenen Methoden zu wählen. Die übrigen Schaltflächen geben dem Nutzer weitere Handlungsmöglichkeiten, wie das Starten und Stoppen des Buzz-Detection-System .
Bewertung des Buzz-Detection-System
Für die Bewertung des Buzz-Detection-System wählt man zwei Zeiträume aus.
Der erste Bewertungszeitraum beträgt knapp zwei Monate. Der zweite Zeitraum beträgt drei Monate.
Man hat sich bewusst für zwei verschiedene Zeiträume entschieden, da in dem zweiten Bewertungszeitraum Festtage (Weihnachten, Silvester) enthalten sind. Mithilfe der zwei Zeiträume möchte man untersuchen, wie das Buzz-Detection-System auf die Feiertage reagiert.
Beiträge, die an Weihnachten oder Silvester erstellt werden, stellen keine Buzzes da. Denn diese Beiträge sind nicht unerwartet.
Insgesamt wurden 213.228 Beiträge mit 23,5 Millionen Kommentaren von 873 verschiedenen Facebook Seiten betrachtet (in beiden Bewertungszeiträumen).
Auf all diese Beiträge wurden nur vier Kodierer angesetzt, die diese Beiträge erstmal per Hand klassifizieren sollten. Sie sollten also alle Beiträge prüfen und als Buzz oder Nicht-Buzz einstufen. Diese Ergebnisse werden später genutzt um zu prüfen, wie gut das Buzz-Detection-System arbeitet.
Im ersten Zeitraum wurden 57.612 der 213.228 Beiträge betrachtet, von denen 120 einen Buzz darstellen.
Die besten Ergebnisse lieferten die logistische Regression und das Support Vector Machine. Die Random Forest Methode sowie das AdaBoost schnitten schlecht ab.
Im zweiten Bewertungszeitraum wurden dann die restlichen 155.616 Beiträge betrachtet. Von denen soll es sich bei 145 Beiträgen um einen Buzz handeln.
Auch in diesem Zeitraum gab es die besten Ergebnisse für die logistische Regression und das Support Vector Machine.
Wenn man die Ergebnisse des Buzz-Detection-System mit denen der Kodierer vergleicht, kommt man auf folgendes Ergebnis. Insgesamt wurden nur 70% der Buzzes von einem der verschiedenen Methoden erkannt.
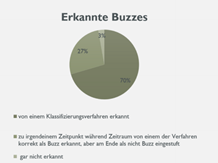
Wenn man die verschiedenen Klassifizierungstechniken jedoch kombiniert, erkennt das Buzz-Detection-System 97,24% der Buzzes.
Weihnachts- oder neujahrsbezogene Beiträge wurden erfolgreich als Nicht-Buzzes eingestuft.
Bewertung der Geschwindigkeiten und anschließendes Ergebnis
Nicht jeder Beitrag geht sofort viral und wird zu einem Buzz. Die Erkennungsgeschwindigkeit sollte vorsichtig interpretiert werden, denn eine lange Erkennungszeit muss nichts Negatives bedeuten.
Mit Hinblick auf die Geschwindigkeit und die Anzahl der korrekt klassifizierten Buzzes lässt sich folgendes sagen: Das Support Vector Machine ist schneller als die Anderen und erkennt viele Buzzes gefolgt von der logistischen Regression. Random Forest und AdaBoost schnitten unerwartet schlecht ab. Das liegt daran, dass sie mehr Variablen zum Arbeiten benötigen. Die Kombination aller Klassifizierungstechniken ist sinnvoller, als sie einzelnd anzuwenden. Sie klassifizieren teilweise unterschiedliche Beiträge und ergänzen sich gut.
SCHLUSSFOLGERUNG
Die Studie weist mehrere Einschränkungen auf, welche Möglichkeiten für künftige Forschungen bietet.
Es wurden nicht alle Beiträge als Buzzes oder Nicht-Buzzes klassifiziert.
Des Weiteren lieferten AdaBoost und Random Forest schlechtere Ergebnisse, weil zu wenige Variablen eingebunden wurden.
Künftige Studien könnten mehrere Variablen einbeziehen und somit fortgeschrittenere Modelle trainieren.
Zukünftige Forschungen könnten auch Variablen untersuchen, die dazu beitragen, Buzzes noch schneller zu erkennen.
Eine weitere Möglichkeit wäre es andere soziale Netzwerke einbinden, wie Twitter oder Instagram.